目录
1 Raft概念
分布式系统中,为了实现一致性,一般采用对称式和非对称式两种server组织方式。
对称式:所有的server都具有相同的功能,客户端可以和任意一个server通信。
非对称式:有一个leader作为与外界通信的角色,其余server不与外界通信,leader会将数据的变更同步到所有的其他server中。
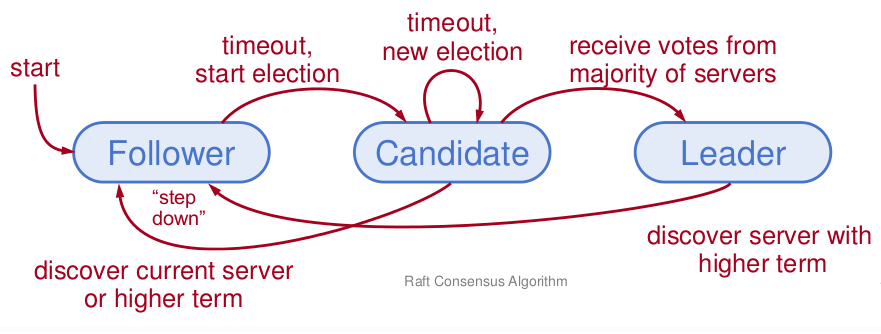
raft采用的第二种方式,也就是leader—based。 raft算法的集群中server共有三种角色,他们分别是:
follower:负责跟随leader,不会主动跟客户端通信,会随着election timeout变成candidate
candidate: candidate为选举过程中的中间状态,当candidate得到大多数的follower的投票,会将自己升级为leader。同时,当已经存在leader后,candidate会将自己降为follower。
leader: 负责与client打交道,一个term表示一轮选举,每一个term中至多存在一个leader,也即可能存在某一个term中选举不出leader来,在这个term的时间范围内,整个集群是无法对外提供服务的。
可以将follower,candidate,leader与美国大选中的角色对应起来。 follower代表议员,candidate代表总统候选人,leader代表总统。
选举过程中遵循的原则为:
-
每一任期(term)中最多只有一个总统
-
总统卸任,举行下一次大选,其余某个或某些议员会被推举为总统候选人,候选人得到多数选票则变成总统,如果同时几个候选人都未得到多数选票,候选人重新选举,重新计票,直到选出总统。
-
总统的提议只有得到议会大多数赞成票才能通过(对比commit)。如果有议员没有回复总统的提议,会一直向该议员传达,直到回复为止。
-
如果候选人遇到总统,总统的term number不小于候选人的term number,则候选人将自己降为议员。否则,证明这个总统是前一任期的总统,而候选人是最新的候选人,候选人继续参与选举。
-
如果两个总统相遇,则term number小的总统将自己降为议员(follower)。
server之间通过RPC通信,三种角色转换图:
为了raft算法的易于理解,raft将算法分为leader election,log replication,safty,membership change几个子问题。下面将一一介绍。
2 leader election
系统刚开始启动的时候,会从所有follower中选择一个或几个candidate(依据哪个follower的timeout先到),然后其余follower为candidate投票(每个follower只能投一票),从candidate中选出leader,leader负责与client通信(所有到follower的请求也会重新指向leader),同时负责向follower发送appendEntry。
如果存在AppendEntry需要发送,那么发送该AppendEntry,如果没有变更命令,则定时发送HeartBeat(没有内容的AppendEntry)给所有的follower,告知它们leader仍然存在。follower收到leader的心跳就会继续保持follower的角色。
Leader发送给follower的AppendEntry只有得到大多数的回复后,leader自身状态机才能执行entry提交,并将结果返回给客户端。同时,leader会向follower发送heartbeat告知follower可以将上一次接收到的log entry提交。
这里存在着这样一种可能: 如果leader将appendEntry发送给follower后就挂了,那么应该怎么处理? 分两种情况:
1):大多数follower已经接收到AppendEntry
2):大多数follower没有接收到AppendEntry
接下来应该重新选举,
对于情况1
-
如果选举出的leader属于大多数接收到Entry中的一个,那么下一次的appendEntry到来的时候,会将前面未提交的entry一并发送给follower,得到大多数的ack回复后一并提交。
-
如果选举出的leader属于少数没有接收到entry中的一个,这种情况不会出现,因为选举限制规定:follower不能给比自己log旧的candidate投票
因此少数派的log会比大多数中的log旧,少数派无法在选举中成为leader。
对于情况2
-
如果选举出的leader属于大多数没有接收到Entry中的一个。由于前一个leader挂掉了,因此客户端知道此次命令执行失败,会选择重试或者放弃等策略(主要看客户端的处理逻辑)。现在的leader也不含这条命令,因此相当于这条命令在集群中执行失败,而集群的状态还是一致的。
-
如果选举出的leader属于少数接收到entry中的一个,那么情形与
情况1中的第一种结果一样。
follower收到leader的heartbeat,则回复leader。如果在follower的timout之后,仍然没有收到leader的heartbeat,follower认为leader已挂,“国不可一日无君”,因此推举自己为candidate,向所有server发送AppendVote RPC为自己拉票。此时存在这三种情况:
1) 自身拉票成功,成为leader。
2) 其他candidate成为leader,则降低自己身份为follower。
3) 没有出现leader,则开启下一轮选举直到选出leader为止。
3 log replication
每个server中都会保存一份log,log中记录了客户端的command。同时存在着一个状态机,状态机负责将log中的command提交,前提是必须在安全的情况下(下面将会解释安全的含义)。状态机按序执行log中的command,每个log中包含了同样的command,且命令的顺序一致,因此状态机在执行的时候能够保证每次执行都会有相同的输出。也就是只要所有的server中的log一致,那么经过状态机的执行,都会得到相同的结果,来保证分布式集群之中的数据一致性。因此,如何确保log一致是一致性算法要解决的问题。 log中的一个单元称为Entry,每个Entry包含了command,index和term
leader通过RPC 将command发送给所有的follower。等到大多数的follower回复leader接收到发送的append entry时(如果有follower没有回复,那么leader会持续向该follower发送append entry),leader会将自己的log entry提交。
leader不会移除自己的log entry,follower在entry与leader不一致时,会移除自己的entry与leader保持一致。
4 safty
保证在非Byzantine条件下,无论是网络延时,分区,丢包,包重复以及无序等情况下,都能返回正确的结果。
需要保证新的leader保存所有前任leader的所有提交。因此,每一任leader中的log都能保证整个系统自启动以来的所有变更,因此状态机执行的时候总能保证分布式环境下的一致性。
实现方式: 在leader选举时,对于log比自己的log旧的candidate,follower拒绝为其投票,由于leader会根据自己的log内容重写follower中的log,因此避免了前任leader的提交记录被修改,使得集群整体状态被改变。比较的方式为: 根据Entry中的index和term来比较,如果term更大,说明更新,如果term一致,log越长即index越大,说明越新。
5 membership change
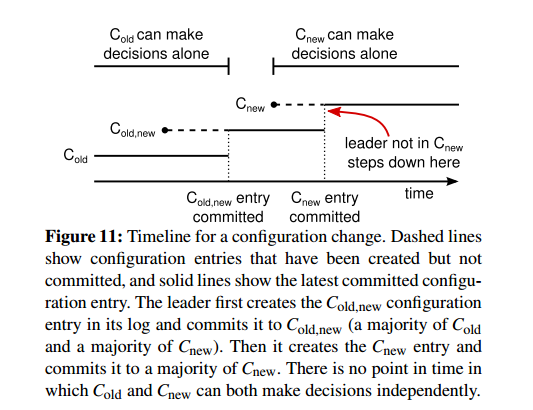
集群中节点的变更,要么是故障,要么是业务需求扩容/缩容。 Raft使用联合一致性阶段(joint consensus)来作为过渡阶段实现配置从旧到新的变化。
集群中配置状态的转换:
-
Cold 已提交,Cold,new 未提交
-
Cold,new 已提交,Cnew 未提交 此时只有拥有 Cold,new 配置的server才会被选为leader。 如果此时,Cold,new 提交失败,那么重新发送Cold,回滚配置。
-
Cnew 已提交 如果在这个阶段存在着Leader election,那么只有具有Cnew 配置的server才能被选为Leader, Leader将Cnew 配置复制到所有的follower,使得整个集群应用新的配置。
如果Cnew 提交时,leader并不包括在新的配置中,那么leader将降为为follower,且不参与大多数的投票。
如果Cnew 提交失败,则需要复制Cold,回滚配置。如果在回滚配置之前发生了Leader Election,那么leader具有Cnew,则将其复制到新集群。如果leader没有Cnew,则会覆盖其他server中的新配置,回到joint consensus状态。

6 参考资料
- http://raftconsensus.github.io
- http://ramcloud.stanford.edu/raft.pdf
- http://raftconsensus.github.io/
- http://raftuserstudy.s3-website-us-west-1.amazonaws.com/raft.mp4
- http://www.infoq.com/cn/articles/coreos-analyse-etcd/