目录
1 背景
在业务发展的早期,对业务数据量没有进行严格的评估,由于业务发展的未知性,也没法做出严格的评估,因此出现多个小业务使用同一个redis缓存的情况。但是随着时间的推移,原来评估的某一个小功能在公司层面变成一个大的方向,造成了redis缓存中某一功能相关的key数量不断上涨,同时qps也相应的上升。 这时对于单一redis实例就容易出现性能瓶颈,包括单个redis实例qps,连接数,IOPS,容量等多方面的限制。
通过升级redis实例能够提升前面提到的性能,但是阿里云单实例版最大只支持64G内存,集群版可以支持256G,但是集群版价格相对于单实例要贵不少,从容量,性能和成本上考虑暂时不用集群版,而是对原有redis实例做拆分。拆分之后,原有实例为一部分功能提供服务,新实例为另一部分功能提供服务,业务之间互相隔离。
2 数据占比
在拆分之前有必要针对redis做一个内存数据分析,看看各种数据的内存占比,做到对于需要拆分的实例内存数据有一个清晰的认识。可以使用阿里云提供的redis-rdb-tools来分析,或者雪球开源的rdr也可以,使用rdr有漂亮的UI展示各类数据的内存占比。
3 数据迁移工具
在做拆分方案之前,先看一看现状,我们要做的是将阿里云redis实例数据拆分一部分到新的redis实例中,新的redis实例同样也是阿里云的redis,阿里云提供了DTS工具可以帮助实现redis的数据迁移,但是目前不支持源实例为阿里云redis,需要阿里云的工程师支持,因此对于存量和增量数据迁移这一块可以由阿里云的工程师支持。
DTS数据迁移只是整个工作中的一部分,DTS工具不能一直启动,那DTS停止数据同步之后,新的数据如何写入到新实例呢?这里需要使用双写机制,即数据既往原有实例写,同时也往新实例写。这一步操作需要业务代码层面保证。另外当所有数据都迁移到新的实例之后,业务的读请求都要访问新的实例,因此需要在业务代码层面设计开关可以切换读请求。当新实例稳定提供读写请求一段时间后,需要将双写停掉,因此双写操作也是需要开关配置的。
4 方案设计
下面看一下整个数据拆分和迁移的方案。假设A为原实例,B为新的实例,需要从A中拆分出小说的数据到B,拆分后由B提供小说的数据存储,A不再为小说提供数据存储。
-
刚开始小说数据的读和写都走A
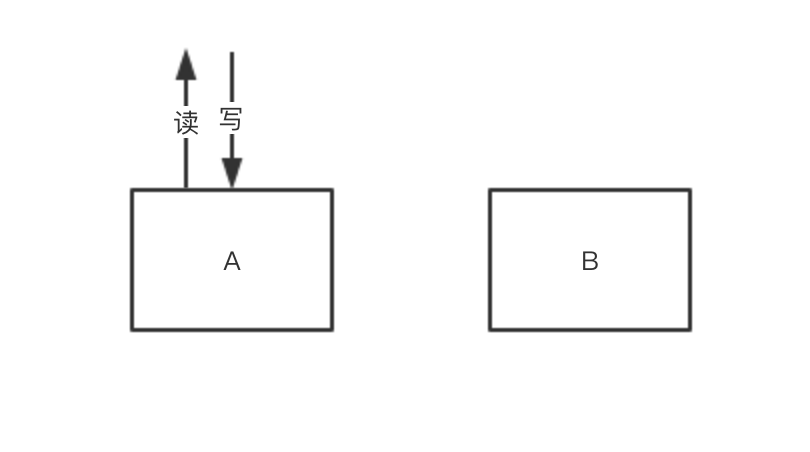
-
联系阿里云工程师将A实例中的数据全量同步到B中,在全量数据同步完成后,开启增量同步。
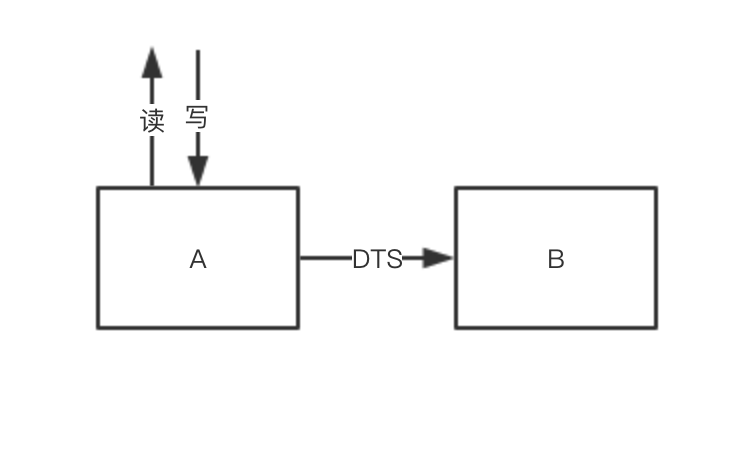
-
验证B中的数据和A中的完全一致,同时增量的数据也不断的同步到B中。
-
只有第3步验证通过后,才能执行第4步。停止DTS数据同步,随即打开双写开关。由于停止DTS数据同步和打开双写开关之间存在着时间差,这个时间差的数据就丢失了,没有写到B中。即使两步之间没有时间差,也可能出现脏数据的问题。因此在这一步之后必须修数据。
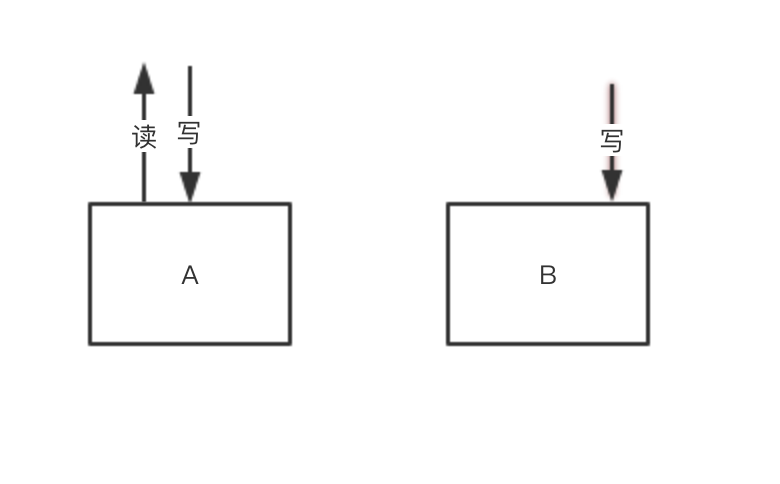
-
修复第4步中丢失的数据。这个修复操作可能会比较繁琐,大体思路就是将第4步中的时间差内(可以向前后放宽一段时间)A中产生的数据写到B中。在写的过程中,可能存在着那一部分数据的更改,因此需要对不一致的数据进行再一次的更新,直到两边的数据一致。
-
执行第6步之前,所有小说数据的读和写还是走的老逻辑,即读写A,A中的数据没有经过任何人为的变更,因此前5步操作并不会对线上服务产生任何影响。 切读,小说数据的读请求走B。当切读后,所有小说数据来自于B,这一步应当随时关注监控,报警,线上反馈,如果有问题,立即将读请求切回到A。然后排查B中的数据问题。直到B中的数据没问题之后,才能再次切读。
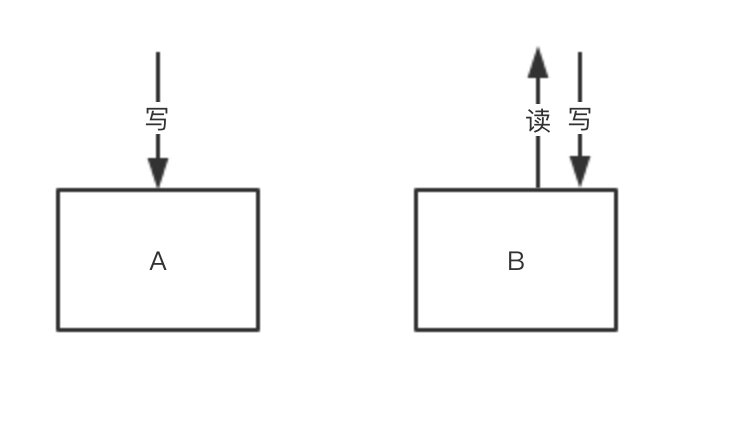
-
现在小说的数据双写A和B,读的是B,当这种情况在线上稳定运行一段时间(一般是以周为记)之后,可以考虑将双写下掉。下掉双写,小说数据的读和写都走B,此时redis缓存的拆分和数据迁移绝大部分已经完成,只剩下数据的清理工作。
-
清理A和B中的数据,将A中所有小说相关的数据移除,将B中所有非小说的数据移除。
-
在业务上去掉开关的逻辑代码。 至此,redis的数据迁移和拆分完成。
5 总结
数据迁移需要注意的点:双写,先切写再切读,读和写需要有独立的开关控制。
双写逻辑会造成一定的性能损失,但是不可避免。如果没有外部工具能够实现A和B之间的数据同步,应该自己实现这样的工具。在切读之前,必须在一个实例中保存有完整的数据,一旦数据迁移有问题,可以随时切回去,必须要有回滚方案。另外,每一次开关操作都伴随着数据的校验,有可能还伴随着数据的清洗,细心是必不可少的。如果对于短时间内的数据不敏感,也可以选择不洗数据。
